文本聚类python fcm |
您所在的位置:网站首页 › 模糊聚类 python › 文本聚类python fcm |
文本聚类python fcm
|
FCM(fuzzy c-means) 模糊c均值聚类融合了模糊理论的精髓。相较于k-means的硬聚类,模糊c提供了更加灵活的聚类结果。因为大部分情况下,数据集中的对象不能划分成为明显分离的簇,指派一个对象到一个特定的簇有些生硬,也可能会出错。故,对每个对象和每个簇赋予一个权值,指明对象属于该簇的程度。当然,基于概率的方法也可以给出这样的权值,但是有时候我们很难确定一个合适的统计模型,因此使用具有自然地、非概率特性的模糊c均值就是一个比较好的选择。 聚类损失函数:
N个样本,分为C类。C是聚类的簇数;i,j是标号;
xi表示第i个样本,xi是具有d维特征的一个样本。cj是j簇的中心,也具有d维度。||*||可以是任意表示距离的度量。 模糊c是一个不断迭代计算隶属度和簇中心的过程,直到他们达到最优。
对于单个样本xi,它对于每个簇的隶属度之和为1。 迭代的终止条件为:
其中k是迭代步数,
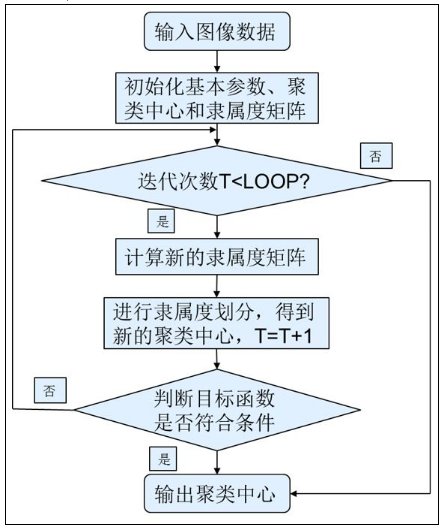
该过程收敛于目标Jm的局部最小值或鞍点。 抛开复杂的算式,这个算法的意思就是:给每个样本赋予属于每个簇的隶属度函数。通过隶属度值大小来将样本归类。 算法步骤:
1、初始化 2、计算质心 FCM中的质心有别于传统质心的地方在于,它是以隶属度为权重做一个加权平均。 3、更新隶属度矩阵
b一般取2。 【转载自】 Fuzzy C-Means(模糊C均值聚类)算法原理详解与python实现 - Yancy的博客 - CSDN博客 https://blog.csdn.net/lyxleft/article/details/88964494 |

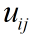 表示 样本i 属于 j类 的隶属度。
表示 样本i 属于 j类 的隶属度。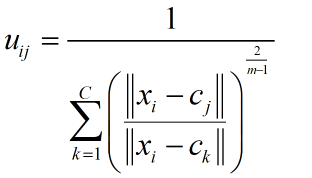

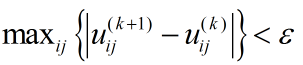
 是误差阈值。上式含义是,继续迭代下去,隶属程度也不会发生较大的变化。即认为隶属度不变了,已经达到比较优(局部最优或全局最优)状态了。
是误差阈值。上式含义是,继续迭代下去,隶属程度也不会发生较大的变化。即认为隶属度不变了,已经达到比较优(局部最优或全局最优)状态了。
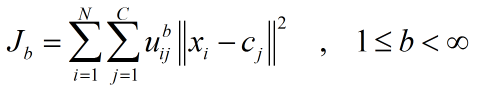
【本文地址】
今日新闻 |
推荐新闻 |